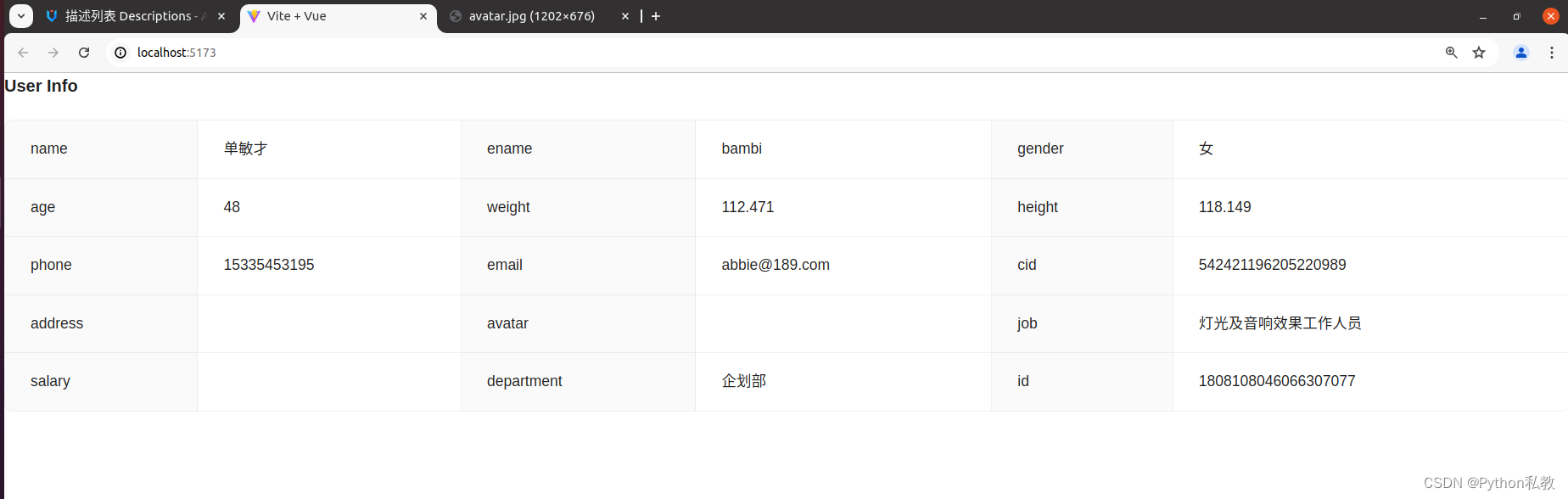
Mixture of A Million Experts
公和众与号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
![]()
目录
0. 摘要
1. 简介
2. 方法
3. 实验
0. 摘要
标准 Transformer 架构中的前馈(feedforward,FFW)层随着隐藏层宽度的增加,计算成本和激活内存呈线性增长。稀疏混合专家(Sparse mixture-of-experts,MoE)架构通过将模型大小与计算成本解耦,已经成为解决这个问题的可行方法,。最近发现的细粒度 MoE 缩放法则表明,更高的粒度会带来更好的性能。然而,由于计算和优化方面的挑战,现有的 MoE 模型仅限于少量的专家。本文介绍了参数高效专家检索(parameter efficient expert retrieval,PEER),一种新颖的层设计,利用乘积 key(product key)技术从大量小专家(超过一百万)中进行稀疏检索。在语言建模任务上的实验表明,PEER 层在性能与计算的权衡方面优于密集的 FFW 和粗粒度的 MoE。通过高效利用大量专家,PEER 在保持计算效率的同时,释放了 Transformer 模型进一步扩展的潜力。
1. 简介
为了打破计算成本和参数数量之间的耦合,许多近期的研究(Shazeer等,2017;Lepikhin等,2020;Fedus等,2022;Zhou等,2022)采用了 MoE 架构,该架构使用一组稀疏激活的(sparsely activated)专家模块(通常是 FFW)来替代单个密集的 FFW。Clark 等(2022)研究了 MoE 语言模型的缩放法则,表明增加专家数量是提高性能的有效方法,而不会增加推理成本。然而,他们的实验表明,MoE 提供的效率增益在达到某一模型大小后会趋于平稳。最近,Krajewski 等(2024)发现这种平稳是由于使用了固定数量的训练样本引起的。当训练样本数量达到计算最优时,MoE 在 FLOP 效率方面始终优于密集模型。此外,他们引入了粒度(活动专家的数量)作为新的缩放轴,并通过实验证明,使用更高的粒度可以提高性能。对这种细粒度 MoE 缩放法则的外推表明,模型容量的持续改进最终将导致一个具有高粒度的大模型,对应于拥有大量小专家的架构。
除了高效缩放之外,拥有大量专家的另一个原因是终身学习(lifelong learning),其中 MoE 作为一种有前途的方法(Aljundi等,2017;Chen等,2023;Yu等,2024;Li等,2024)出现。例如,Chen等(2023)表明,通过简单地添加新专家并适当地正则化它们,MoE 模型可以适应连续的数据流。冻结旧专家并只更新新专家可以防止灾难性遗忘,并通过设计保持可塑性。在终身学习环境中,数据流可以无限长或永无止境(Mitchell等,2018),这需要一个不断扩展的专家池。
尽管高效缩放和终身学习都需要能够处理大量专家的 MoE 设计,但据我们所知,唯一支持超过一万个专家的架构是词专家混合(Mixture of Word Experts,MoWE)(dos Santos等,2023)。然而,MoWE 是特定于语言的,并使用固定的路由方案。理论和实验证据(Clark等,2022;Dikkala等,2023)强调了学到的路由器(router)相对于非可训练路由器的优势。因此,具有学到的路由器且可扩展到超过一百万专家的 MoE 设计仍然是一个值得探索的领域。
2. 方法
在本节中,我们介绍参数高效专家检索(PEER)层,这是一种使用乘积 key(product keys)(Lample等,2019)作为路由器并将单神经元 MLP 作为专家的混合专家架构。图 2 展示了 PEER 层的计算过程。

PEER 概述。形式上,一个 PEER 层是一个函数 f: R^n→R^m,它由三部分组成:
- 一个包含 N 个专家的池 E := {e_i}^N_(i=1),每个专家 e_i: R^n→R^m 具有与 f 相同的签名,
- 一个对应的 N 个乘积 key 集合 K := {k_i}^N_(i=1)
- 一个将输入向量 x∈R^n 映射到 query 向量 q(x) 的网络 q: R^n→R^d
令 T_k 表示前 k 个操作符。给定输入 x,我们首先检索 query q(x) 与对应的乘积 key 内积最高的 k 个专家的子集。
![]()
然后我们对这些前 k 个专家的 query-key 内积应用非线性激活(如 softmax 或 sigmoid),以获得路由器得分。
![]()
最后,我们通过以路由器得分为权重线性组合专家输出来计算输出。
![]()
乘积 key 检索。由于我们打算使用非常大量的专家(N ≥ 10^6),直接计算公式(1)中的前 k 个索引会非常昂贵。因此,我们在这里应用乘积 key 检索技术。我们不使用 N 个独立的 d 维向量作为 key k_i,而是通过连接来自两个独立的 d/2 维子 key 集合 C,C′ ⊆ R^(d/2) 的向量来创建它们:
![]()
注意这里的 C,C′ 的基数(cardinality)为 √N,而 c,c′ 的维度为 d/2。所以在实践中,我们选择 N 为一个完全平方数, d 为一个偶数。
这种笛卡尔积结构的 K 使我们能够高效地找到前 k 个专家。我们不再将 q(x) 与 K 中的所有 N 个 key 进行比较并选择前 k 个匹配项,而是将向量 q(x) 分成两个子 query q_1 和 q_2,并分别将前 k 操作应用于子 query 和子 key 之间的内积:
![]()
这产生了一组 k^2 个候选 key
![]()
并且数学上保证了 K 中与 q(x) 最相似的前 k 个 key 在这个候选集中。此外,候选 key 与 q(x) 之间的内积只是子 key 和子 query 之间内积的和:
![]()
因此,我们可以再次将前 k 操作符应用于这 k^2 个内积,以从原始的乘积 key 集合 K 中获得前 k 个匹配 key。正如 Lample 等(2019)所解释的那样,这将公式(1)中前 k 个专家检索的复杂度从通过穷尽搜索的 O(Nd) 降低到 O((√N + k^2)d)。
参数高效专家和多头检索。与其他 MoE 架构不同,这些架构通常将每个专家的隐藏层设置为与其他 FFW 层相同的大小,而在 PEER 中,每个专家 e_i 是一个单独的 MLP,换句话说,它只有一个带有单个神经元的隐藏层:
![]()
其中 v_i, u_i 不是矩阵,而是与 x 具有相同维度的向量,σ 是非线性激活函数,如 ReLU 或 GELU。为了简洁起见,我们省略了偏置项。
我们不改变单个专家的大小,而是通过使用多头检索来调整 PEER 层的表达能力,类似于 Transformer 中的多头注意机制和 PKM 中的多头内存。具体来说,我们使用 h 个独立的网络,而不是一个,每个网络计算其自己的 query 并检索一个单独的专家集。然而,不同的头共享相同的专家池和相同的乘积 key 集合。h 个头的输出简单地相加:

可以验证,当每个头仅检索一个专家时(k=1),使用具有 h 个头的 PEER 层与使用具有 h 个隐藏神经元的一个专家是相同的:

其中 W=[u1,⋯ ,uh],V=[v1,⋯ ,vh]。换句话说,PEER 通过聚合从共享库中检索到的 h 个单独的 MLP 动态组装一个具有 h 个神经元的 MLP。相比于使用具有多个隐藏神经元的 MLP 作为专家的现有 MoE 方法,这种设计允许专家之间共享隐藏神经元,从而增强知识传递和参数效率。

算法 1 展示了 PEER 前向传递的简化实现,将参数高效专家权重存储在嵌入层中,并将它们与 einsum 操作相结合。通过添加额外的线性门控权重,可以轻松扩展此实现以支持 GLU 变体的专家(Shazeer,2020)。在实践中,高效实现可能需要专用硬件内核来加速嵌入查找和与 einsum 操作的融合。
为什么需要大量的小专家?给定一个 MoE 层,我们可以通过三个超参数来表征它:总参数数量 P、每个 token 的活跃的参数数量 P_active 和单个专家的大小 P_expert。Krajewski 等(2024)表明,MoE 模型的缩放法则具有以下形式:
![]()
其中,L 是最终测试损失,a,b,g,γ,α,β 是常数,D 是训练样本的总数,粒度 G 是活跃专家的数量:

为了提高模型性能,我们需要扩大 P,D,G。另一方面,必须限制 P_active,因为计算和内存成本主要由训练和推理期间的活跃参数决定。特别是,与 P_active 相关的内存占用必须乘以 batch 中的样本数量,而 P 的内存成本与 batch 大小和序列长度无关,因为只需要存储模型的一份副本。
因此,我们希望增加 P 和 G,但不增加 P_active。由于专家大小 P_expert = P_active / G 和专家数量 N = P / P_expert = P⋅G / P_active,这意味着我们应该减小每个专家的大小 P_expert 并增加专家的数量 N。因此,我们需要大量的小专家。
通常,对于具有单隐藏层的 MLP 专家,P_expert = (2·d_model + 1)·d_expert 和 P_active = (2·d_model + 1)·d_active,其中 d_model, d_expert 和 d_active 分别是 Transformer 的隐藏维度、一个专家使用的隐藏神经元数量以及每个 token 激活的总隐藏神经元数量。
在 PEER 的情况下,我们通过设置 d_expert = 1 来使用最小的专家大小,且激活的(activated)神经元数量是检索头的数量乘以每个头检索的专家数量:d_active = hk。因此,PEER 的粒度总是 G = P_active / P_expert = d_active / d_expert = hk。
3. 实验



结果表明,在所考虑的值范围内,更高的 hk 通常会带来更好的性能。值得注意的是,随着 hk 的增加,最佳的 h 也会增加。然而,性能逐渐趋于饱和,并且增加活跃专家的数量也会增加设备的内存消耗,并可能需要额外的加速器设备。因此,在实际应用中,应根据性能、设备数量和计算资源需求之间的权衡来选择合适的 hk 值。